Google ColaboratoryのRランタイムでCSVを操作してみる
ColaboratoryはGoogle社が提供クラウド型のJupyter Notebook環境です。 Googleアカウントがあれば、無料で使用できます。
今回はこのColaboratoryのR言語のランタイムを使用してCSVを操作する方法を紹介します。
この記事はFOLIO Advent Calendar 2019の12月12日の代打記事でもあります。
Google Colaboratory
前述の通り、ColaboratoryはGoogle社が提供クラウド型のJupyter Notebook環境です。 2コアのCPUとGPU、TPUが無料で使用できます。スゴイ!
動作するランタイムは、以下の4つの言語です
- Python 2
- Python 3
- R
- Swift(for TensorFlow)
- Swiftコンパイラを拡張してTensorFlowを使えるようにしたもの
また、ColaboratoryはGoogle Driveの一アプリケーションであるため、GSuiteに属するためエンタープライズユースも可能です。
Google ColaboratoryでRを動かす
ColaboratoryはデフォルトでPython2とPython3が使用できるようになっていますが、R言語も使用が可能です。

Rを動かすためには以下のJSONファイルを.ipynb拡張子で保存し、アップロードすることで実現が可能となります。
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "",
"provenance": []
},
"kernelspec": {
"name": "ir",
"display_name": "R"
}
},
"cells": []
}

実際Rが動くか試すためにRのバージョン情報を表示してみます。
R.version
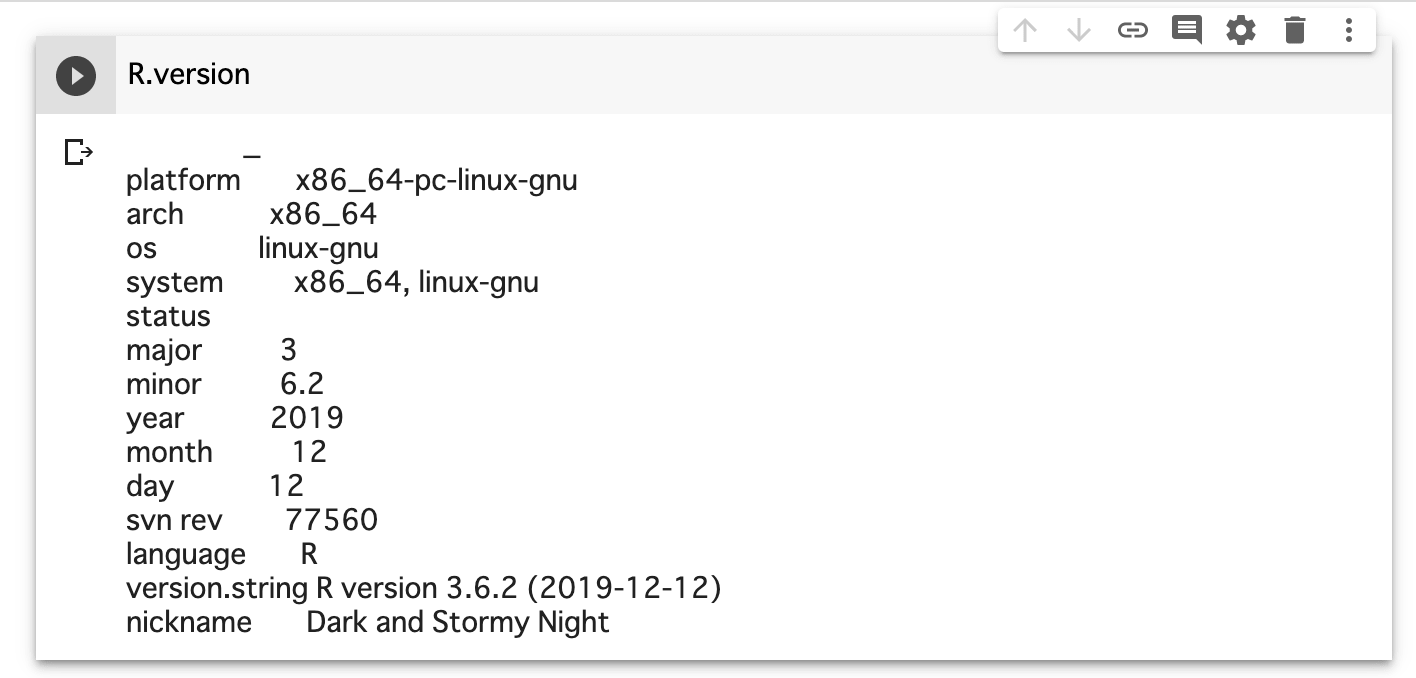
執筆時点で最新版のRが使用できることが確認できました。 必ず最新版とは限らないですが、ほぼ最新版が使用できるようになっているのだと思われます。
使用したいファイルをアップロード
ColaboratoryのRランタイムでは、PythonのようにGoogle Driveのマウントができないですが、ファイルはアップロードできます。
今回は、免許・許可・登録等を受けている業者一覧から取得した金融商品取引業者を最低限のCSVデータにしたものをアップロードしてみます。 デフォルトのワーキングディレクトリは/contentであり、ファイルはこの配下にアップロードされます。
実際アップロードした結果、ファイルがアップロードされていることが確認できます。
list.files()
# 1. 'financial_instruments_traders.csv'
# 2. 'sample_data'
CSVを操作してみる
Rの標準のread.csvを使用してもよいですが、今回は高速なデータフレームでおなじみのdata.tableを使用してみます。
install.packages("data.table")
library(data.table)
# CPUが2コアあるので2コア分設定
setDTthreads(2)
# dplyrはデフォルトでインストールされている
library(dplyr)
data.tableとdplyrの呼び出しをしておき以降それらを使えるようにしておきます。 まずは、CSVデータを読み取り先頭を表示してみます。
financial_instruments_traders_data <- fread('financial_instruments_traders.csv')
financial_instruments_traders_data %>% head

無事読み込めました。ここからはRの世界です。
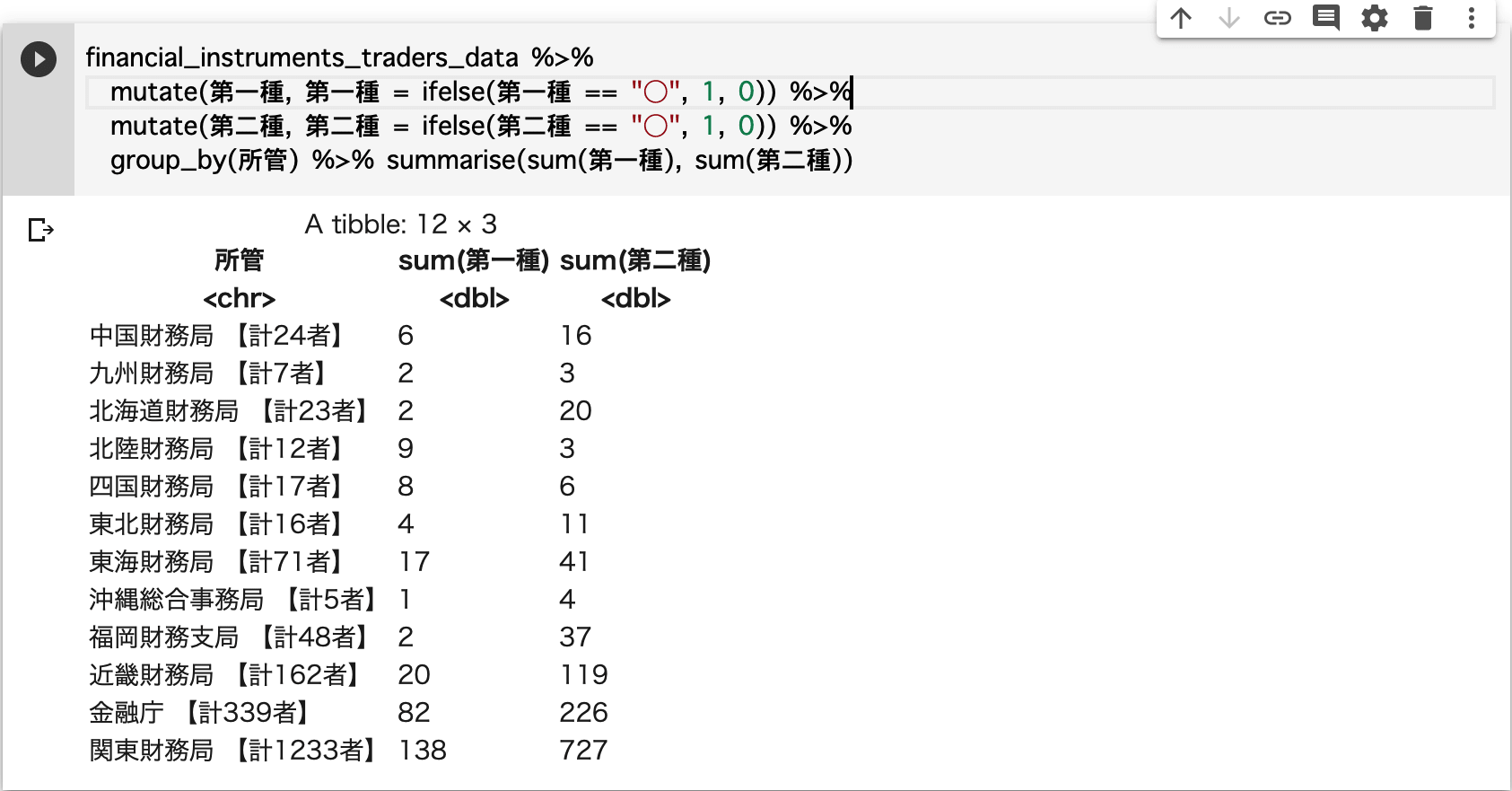
たとえば、各所管ごとの第一種金融取引業者と第二種金融取引業者の合計数を出したいとした場合は
financial_instruments_traders_data %>%
mutate(第一種, 第一種 = ifelse(第一種 == "○", 1, 0)) %>%
mutate(第二種, 第二種 = ifelse(第二種 == "○", 1, 0)) %>%
group_by(所管) %>% summarise(sum(第一種), sum(第二種))
とすることで出力できます。
もちろんプロットも可能です。今回はggplot2を使ってプロットしてみます。 まずは必要なライブラリを準備します。
install.packages(c("reshape2", "ggsci"))
library(reshape2)
library(ggsci)
# ggplot2はデフォルトでインストールされている
library(ggplot2)
先程の例のデータを横並びの棒グラフで表現したいとした場合、以下のようにしてグラフを得ます。
summarised_group_by_shokan <- financial_instruments_traders_data %>%
mutate(第一種, FirstKind = ifelse(第一種 == "○", 1, 0)) %>%
mutate(第二種, SecondKind = ifelse(第二種 == "○", 1, 0)) %>%
group_by(position = 所管) %>%
summarise(FirstKindSum = sum(FirstKind), SecondKindSum = sum(SecondKind))
g <- ggplot(melt(summarised_group_by_shokan), aes(x = position, y = value, fill = variable))
g <- g + geom_bar(stat = "identity", position = "dodge")
g <- g + scale_fill_nejm()
plot(g)
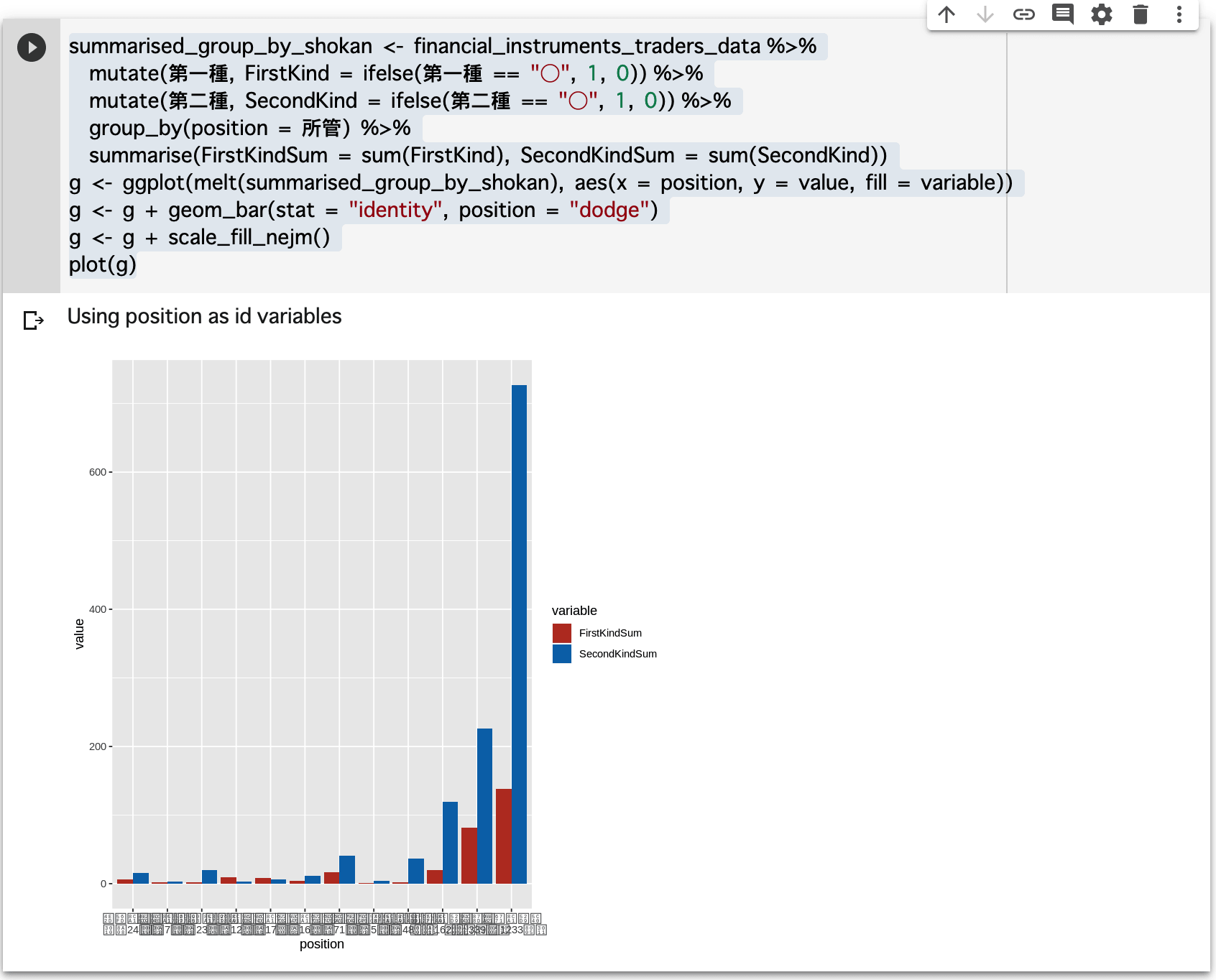
残念ながら日本語が文字化けてしまっています。 ローカル環境ではggplot2のtheme関数を使用することで解決できますが、Colaboratoryでは解決方法がわかりませんでした。
終わりに
Google ColaboratoryのRランタイムでCSVを操作する方法を紹介しました。 RはPythonのPandas以上の柔軟性があり、統計ライブラリが豊富です。 比較的容易に記述でき、Jupyter Notebookとして記録できるので、チームでデータをシェアする際などに活躍すると思います。
Colaboratoryにおける日本語のプロットについて問題を残したままになってしまいました。 もし解決方法ご存じの方いらっしゃいましたらご教示ください。
参考になった・面白かったと感じていただけましたら、サポートいただけると励みになります。
![]() サポートする
サポートする